
python基础知识
python基础知识
python解释器
CPython
这个解释器是用C语言开发的,所以叫 CPython,在命名行下运行python,就是启动CPython解释器 CPython是使用最广的Python解释器
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强
PyPy
PyPy是另一个Python解释器,它的目标是执行速度 PyPy采用JIT技术,对Python代进行动态编译,所以可以显著提高Python代码的执行速度
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器 可以直接把Python代码编译成.Net的字节码。
字符集和字符编码
计算机屏幕上看到实体化的文字,在计算机存储介质中存放的实际是二进制的比特流 两者之间的转换规则就需要一个统一的标准

字符集
字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
为什么那么多字符集
问题实际非常容易回答。问问自己为什么我们的插头拿到英国就不能用了呢?为什么显示器同时有DVI,VGA,HDMI,DP这么多接口呢?很多规范和标准在最初制定时并不会意识到这将会是以后全球普适的准则,或者处于组织本身利益就想从本质上区别于现有标准。于是,就产生了那么多具有相同效果但又不相互兼容的标准了。 说了那么多我们来看一个实际例子,下面就是屌这个字在各种编码下的十六进制和二进制编码结果,怎么样有没有一种很屌的感觉?
UTF-8
0xE5B18C
111001011011000110001100
UTF-16
0x5C4C
101110001001100
GBK
0x8CC5
1000110011000101
常见字符集
ASCII 字符集:
ASCII编码每个字母或符号占1byte(8bits),并且8bits的最高位是0,因此ASCII能编码的字母和符号只有128个。有一些编码把8bits最高位为1的后128个值也编码上,使得1byte可以表示256个值,但是这属于扩展的ASCII,并非标准ASCII。通常所说的标准ASCII只有前128个值!
ASCII编码几乎被世界上所有编码所兼容(UTF16和UTF32是个例外),因此如果一个文本文档里面的内容全都由ASCII里面的字母或符号构成,那么不管你如何展示该文档的内容,都不可能出现乱码的情况。
GB2312 字符集:
最早一版的中文编码,每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。在GB2312中收录了6763个汉字以及682个特殊符号,已经囊括了生活中最常用的所有汉字。
GBK 字符集:
由于GB2312只有6763个汉字,我汉语博大精深,只有6763个字怎么够?于是GBK中在保证不和GB2312、ASCII冲突(即兼容GB2312和ASCII)的前提下,也用每个字占据2bytes的方式又编码了许多汉字。经过GBK编码后,可以表示的汉字达到了20902个,另有984个汉语标点符号、部首等。值得注意的是这20902个汉字还包含了繁体字,但是该繁体字与台湾Big5编码不兼容,因为同一个繁体字很可能在GBK和Big5中数字编码是不一样的。
Unicode 字符集:
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准
ASCII编码是1个字节,而Unicode编码通常是2个字节
它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字
字符编码
编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
常见编码方式:
ASCII 编码:
将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。
UTF-8 编码:
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。
生成器、迭代器和可迭代对象
迭代器和可迭代对象
可迭代对象包含迭代器
如果一个对象拥有__iter__方法,其是可迭代对象;如果一个对象拥有next方法,其是迭代器
定义可迭代对象,必须实现__iter__方法;定义迭代器,必须实现__iter__和next方法
生成器是一种特殊的迭代器
在使用生成器时,我们创建一个函数;在使用迭代器时,我们使用内置函数iter()和next()
在生成器中,我们使用关键字‘yield’来每次生成/返回一个对象
生成器中有多少‘yield’语句,你可以自定义
每次‘yield’暂停循环时,生成器会保存本地变量的状态
迭代器并不会使用局部变量,它只需要一个可迭代对象进行迭代
使用类可以实现你自己的迭代器,但无法实现生成器
生成器运行速度快,语法简洁,更简单
迭代器更能节约内存
可迭代对象,迭代器和生成器之间的关系如下

Pipenv依赖管理工具
使用 pipdeptree 工具来管理依赖树
pip-autoremove可以删除依赖包
私有仓库
安装pypiserver
安装htpasswd的相关依赖
htpasswd生成上传密码
创建python包存放的目录,可以放个whl包进去
开启服务
pip安装
查看库中常用模块
linux后台执行py脚本
程序后台运行
nohup.out中显示不出来python程序中print的东西,这是因为python的输出有
缓冲,导致nohup.out并不能够马上看到输出 python 有个-u参数,使得python不启用缓冲
还有一种方式(未尝试过)
代码调试技巧
Python 3.7,则无需导入任何内容,只需在代码中要放入调试器的位置调用breakpoint()
Python 3.6及更早版本中,你可以通过显式导入pdb来执行相同的操作,像breakpoint()一样,pdb.set_trace()会将你带入pdb调试器
库和常用方法
变量存储工具方法
什么是酸洗和去除?
Pickle模块接受任何Python对象并将其转换为字符串表示形式,并使用dump函数将其转储到文件中,此过程称为pickling 从存储的字符串表示中检索原始Python对象的过程称为unpickling
序列排序
Python中拥有内置函数实现排序,可以直接调用它们实现排序功能
list.sort(): 直接修改列表
sorted(): 从一个可迭代对象构建一个新的排序列表
不管是 list.sort 方法还是 sorted 函数,都有两个可选的关键字参数
list.sort(cmp=None, key=None, reverse=False)
cmp -- 可选参数, 如果指定了该参数会使用该参数的方法进行排序
key -- 主要是用来进行比较的元素,只有一个参数,函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序
reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)
sorted(iterable, cmp=None, key=None, reverse=False)
erable -- 可迭代对象
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出 此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序
reverse -- 排序规则,reverse = True 降序 ,reverse = False 升序(默认)
sort ()与sorted()区别
sort() 是应用在 list 上的方法,sorted() 可以对所有可迭代的对象进行排序操作 list 的 sort() 方法返回的是对已经存在的列表进行操作,无返回值 而内建函数 sorted() 方法返回的是一个新的 list,而不是在原来的基础上进行的操作
单关键字排序
多关键字排序
使用 itemgetter() 方式会运行的稍微快点,如果你对性能要求比较高的话就使用 itemgetter() 方式
import路径问题
判断是否有中文
分割字符串并转换类型
检查对象是否可调用
随机打乱多个数组
pandas读写csv
classmethod 和 staticmethod
优雅判断数字所属等级
有从 A 到 F 的 5 个等级,现要判断某个数值(从 0 到 1 之间)所属的等级 举例,如数值 >= 0.9,则属于 A;若数值 >= 0.8,则属于 B;以此类推
取整操作
其他库
python cookbook记录
数据结构和算法
最大或最小的 N 个元素
怎样从一个集合中获得最大或者最小的 N 个元素列表?
heapq 模块有两个函数:nlargest() 和 nsmallest() 可以完美解决这个问题。
两个函数都能接受一个关键字参数,用于更复杂的数据结构中:
译者注:上面代码在对每个元素进行对比的时候,会以 price 的值进行比较
如果你想在一个集合中查找最小或最大的 N 个元素,并且 N 小于集合元素数量,那么这些函数提供了很好的性能。因为在底层实现里面,首先会先将集合数据进行堆排序后放入一个列表中:
堆数据结构最重要的特征是 heap[0] 永远是最小的元素。并且剩余的元素可以很容易的通过调用heapq.heappop() 方法得到,该方法会先将第一个元素弹出来,然后用下一个最小的元素来取代被弹出元素(这种操作时间复杂度仅仅是$Olog(N)$,$N$是堆大小)。
小结:
当要查找的元素个数相对比较小的时候,函数 nlargest() 和 nsmallest() 是很合适的。
如果你仅仅想查找唯一的最小或最大(N=1)的元素的话,那么使用 min() 和max() 函数会更快些。
类似的,如果 N 的大小和集合大小接近的时候,通常先排序这个集合然后再使用切片操作会更快点(sorted(items)[:N] 或者是 sorted(items)[-N:])。
需要在正确场合使用函数 nlargest() 和 nsmallest() 才能发挥它们的优势(如果N 快接近集合大小了,那么使用排序操作会更好些)。
实现一个优先级队列
怎样实现一个按优先级排序的队列?并且在这个队列上面每次 pop 操作总是返回优先级最高的那个元素
利用 heapq 模块实现了一个简单的优先级队列:
仔细观察可以发现,第一个 pop() 操作返回优先级最高的元素。另外注意到如果两个有着相同优先级的元素(foo 和 grok ),pop 操作按照它们被插入到队列的顺序返回的。
在上面代码中,队列包含了一个 (-priority, index, item) 的元组。优先级为负数的目的是使得元素按照优先级从高到低排序。这个跟普通的按优先级从低到高排序的堆排序恰巧相反。 index 变量的作用是保证同等优先级元素的正确排序。通过保存一个不断增加的index 下标变量,可以确保元素按照它们插入的顺序排序。而且,index 变量也在相同优先级元素比较的时候起到重要作用
通过引入另外的 index 变量组成三元组 (priority, index, item) ,就能很好的避免上面的错误,因为不可能有两个元素有相同的 index 值。Python 在做元组比较时候,如果前面的比较已经可以确定结果了,后面的比较操作就不会发生了:
如果你想在多个线程中使用同一个队列,那么你需要增加适当的锁和信号量机制。
字典的运算
怎样在数据字典中执行一些计算操作(比如求最小值、最大值、排序等等)?
考虑下面的股票名和价格映射字典:
为了对字典值执行计算操作,通常需要使用 zip() 函数先将键和值反转过来。比如,下面是查找最小和最大股票价格和股票值的代码
类似的,可以使用 zip() 和 sorted() 函数来排列字典数据:
如果你在一个字典上执行普通的数学运算,你会发现它们仅仅作用于键,而不是值。
需要注意的是在计算操作中使用到了 (值,键) 对。当多个实体拥有相同的值的时候,键会决定返回结果。比如,在执行 min() 和 max() 操作的时候,如果恰巧最小或最大值有重复的,那么拥有最小或最大键的实体会返回:
查找两字典的相同点
为了寻找两个字典的相同点,可以简单的在两字典的 keys() 或者 items() 方法返回结果上执行集合操作。
这些操作也可以用于修改或者过滤字典元素。比如,假如你想以现有字典构造一个排除几个指定键的新字典。下面利用字典推导来实现这样的需求:
小结:
一个字典就是一个键集合与值集合的映射关系。字典的 keys() 方法返回一个展现键集合的键视图对象。键视图的一个很少被了解的特性就是它们也支持集合操作,比如集合并、交、差运算。所以,如果你想对集合的键执行一些普通的集合操作,可以直接使用键视图对象而不用先将它们转换成一个 set。 字典的 items() 方法返回一个包含 (键,值) 对的元素视图对象。这个对象同样也支持集合操作,并且可以被用来查找两个字典有哪些相同的键值对。 尽管字典的 values() 方法也是类似,但是它并不支持这里介绍的集合操作。某种程度上是因为值视图不能保证所有的值互不相同,这样会导致某些集合操作会出现问题。不过,如果你硬要在值上面执行这些集合操作的话,你可以先将值集合转换成 set,然后再执行集合运算就行了。
删除序列相同元素并保持顺序
如果你想消除元素不可哈希(比如 dict 类型)的序列中重复元素的话
这里的 key 参数指定了一个函数,将序列元素转换成 hashable 类型。
如果你想基于单个字段、属性或者某个更大的数据结构来消除重复元素,第二种方案同样可以胜任。
命名切片
内置的 slice() 函数创建了一个切片对象,可以被用在任何切片允许使用的地方。
如果你有一个切片对象 a,你可以分别调用它的 a.start , a.stop , a.step 属性来获取更多的信息。
还能通过调用切片的 indices(size) 方法将它映射到一个确定大小的序列上,这个方法返回一个三元组 (start, stop, step) ,所有值都会被合适的缩小以满足边界限制,从而使用的时候避免出现 IndexError 异常。
字符串和文本
使用多个界定符分割字符串
函数 re.split() 是非常实用的,因为它允许你为分隔符指定多个正则模式。比如,在上面的例子中,分隔符可以是逗号,分号或者是空格,并且后面紧跟着任意个的空格。只要这个模式被找到,那么匹配的分隔符两边的实体都会被当成是结果中的元素返回。返回结果为一个字段列表,这个跟 str.split() 返回值类型是一样的。
当你使用 re.split() 函数时候,需要特别注意的是正则表达式中是否包含一个括号捕获分组。如果使用了捕获分组,那么被匹配的文本也将出现在结果列表中。
用 Shell 通配符匹配字符串
使用 Unix Shell 中常用的通配符 (比如 .py , Dat[0-9].csv 等) 去匹配文本字符串
fnmatch 模块提供了两个函数——fnmatch() 和 fnmatchcase() ,可以用来实现这样的匹配。
fnmatch() 函数使用底层操作系统的大小写敏感规则 (不同的系统是不一样的) 来匹配模式。
如果你对这个区别很在意,可以使用 fnmatchcase() 来代替。它完全使用你的模 式大小写匹配
fnmatch() 函数匹配能力介于简单的字符串方法和强大的正则表达式之间。
如果在数据处理操作中只需要简单的通配符就能完成的时候,这通常是一个比较合理的方案。
如果你的代码需要做文件名的匹配,最好使用 glob 模块。
字符串匹配和搜索
匹配或者搜索特定模式的文本
如果你想匹配的是字面字符串,那么你通常只需要调用基本字符串方法就行,比如str.find() , str.endswith() , str.startswith() 或者类似的方法
对于复杂的匹配需要使用正则表达式和 re 模块。为了解释正则表达式的基本原理,假设你想匹配数字格式的日期字符串比如 11/27/2012 ,你可以这样做
如果你想使用同一个模式去做多次匹配,你应该先将模式字符串预编译为模式对象。
match() 总是从字符串开始去匹配,如果你想查找字符串任意部分的模式出现位置,使用 findall() 方法去代替
在定义正则式的时候,通常会利用括号去捕获分组。
捕获分组可以使得后面的处理更加简单,因为可以分别将每个组的内容提取出来。
findall() 方法会搜索文本并以列表形式返回所有的匹配。如果你想以迭代方式返回匹配,可以使用 finditer() 方法来代替
核心步骤就是先使用 re.compile() 编译正则表达式字符串,然后使用 match() , findall() 或者 finditer() 等方法。
字符串搜索和替换
对于简单的字面模式,直接使用 str.replace() 方法即可
对于复杂的模式,请使用 re 模块中的 sub() 函数。为了说明这个,假设你想将形式为 11/27/2012 的日期字符串改成 2012-11-27 。示例如下:
sub() 函数中的第一个参数是被匹配的模式,第二个参数是替换模式。反斜杠数字比如 \3 指向前面模式的捕获组号。
对于更加复杂的替换,可以传递一个替换回调函数来代替
一个替换回调函数的参数是一个 match 对象,也就是 match() 或者 find() 返回的对象。使用 group() 方法来提取特定的匹配部分。回调函数最后返回替换字符串。 如果除了替换后的结果外,你还想知道有多少替换发生了,可以使用 re.subn()来代替。
将 Unicode 文本标准化
删除字符串中不需要的字符
去掉文本字符串开头,结尾或者中间不想要的字符,比如空白。
strip() 方法能用于删除开始或结尾的字符。lstrip() 和 rstrip() 分别从左和从右执行删除操作。默认情况下,这些方法会去除空白字符,但是你也可以指定其他字符。
这些 strip() 方法在读取和清理数据以备后续处理的时候是经常会被用到的。比如,你可以用它们来去掉空格,引号和完成其他任务。 但是需要注意的是去除操作不会对字符串的中间的文本产生任何影响。
如果你想处理中间的空格,那么你需要求助其他技术。比如使用 replace() 方法或者是用正则表达式替换。
审查清理文本字符串
一些无聊的幼稚黑客在你的网站页面表单中输入文本”pýtĥöñ”,然后你想将这些字符清理掉。
文本清理问题会涉及到包括文本解析与数据处理等一系列问题。在非常简单的情形下,你可能会选择使用字符串函数 (比如 str.upper() 和 str.lower() ) 将文本转为标准格式。使用 str.replace() 或者 re.sub() 的简单替换操作能删除或者改变指定的字符序列。你同样还可以使用 2.9 小节的 unicodedata.normalize() 函数将 nicode 文本标准化。
字符串对齐
对于基本的字符串对齐操作,可以使用字符串的 ljust() , rjust() 和 center()方法。
所有这些方法都能接受一个可选的填充字符。
函数 format() 同样可以用来很容易的对齐字符串。你要做的就是使用 <,> 或者 ^字符后面紧跟一个指定的宽度。
如果你想指定一个非空格的填充字符,将它写到对齐字符的前面即可
当格式化多个值的时候,这些格式代码也可以被用在 format() 方法中。
format() 函数的一个好处是它不仅适用于字符串。它可以用来格式化任何值,使得它非常的通用。比如,你可以用它来格式化数字:
在新版本代码中,你应该优先选择 format() 函数或者方法。format() 要比% 操作符的功能更为强大。并且 format() 也比使用 ljust() , rjust() 或 center() 方法更通用,因为它可以用来格式化任意对象,而不仅仅是字符串。
以指定列宽格式化字符串
使用 textwrap 模块来格式化字符串的输出。比如,假如你有下列的长字符串:
下面演示使用 textwrap 格式化字符串的多种方式:
textwrap 模块对于字符串打印是非常有用的,特别是当你希望输出自动匹配终端大小的时候。你可以使用 os.get_terminal_size() 方法来获取终端的大小尺寸。
fill() 方法接受一些其他可选参数来控制 tab,语句结尾等。
在字符串中处理 html 和 xml
字符串令牌解析
迭代器与生成器
顺序迭代合并后的排序迭代对象
有一系列排序序列,想将它们合并后得到一个排序序列并在上面迭代遍历
heapq.merge() 函数可以帮你解决这个问题
heapq.merge 可迭代特性意味着它不会立马读取所有序列。这就意味着你可以在非常长的序列中使用它,而不会有太大的开销。
要强调的是 heapq.merge() 需要所有输入序列必须是排过序的。特别的,它并不会预先读取所有数据到堆栈中或者预先排序,也不会对输入做任何的排序检测。
它仅仅是检查所有序列的开始部分并返回最小的那个,这个过程一直会持续直到所有输入序列中的元素都被遍历完。
文件与 IO
数据编码和处理
函数
给函数参数增加元信息
写好了一个函数,然后想为这个函数的参数增加一些额外的信息,这样的话其他使用者就能清楚的知道这个函数应该怎么使用。
使用函数参数注解是一个很好的办法,它能提示程序员应该怎样正确使用这个函数。例如,下面有一个被注解了的函数:
python 解释器不会对这些注解添加任何的语义。它们不会被类型检查,运行时跟没有加注解之前的效果也没有任何差距。
尽管你可以使用任意类型的对象给函数添加注解 (例如数字,字符串,对象实例等等),不过通常来讲使用类或者字符串会比较好点。
函数注解只存储在函数的 __annotations__ 属性中
尽管注解的使用方法可能有很多种,但是它们的主要用途还是文档。
因为 python并没有类型声明,通常来讲仅仅通过阅读源码很难知道应该传递什么样的参数给这个函数。
这时候使用注解就能给程序员更多的提示,让他们可以正确的使用函数。
ps:这里可以结合元类,为参数做类型检测(narutohyc个人想法,还未实现)
将单方法的类转换为函数
你有一个除 __init__() 方法外只定义了一个方法的类。为了简化代码,你想将它转换成一个函数
大部分情况下,你拥有一个单方法类的原因是需要存储某些额外的状态来给方法使用。
带额外状态信息的回调函数
你的代码中需要依赖到回调函数的使用 (比如事件处理器、等待后台任务完成后的回调等),并且你还需要让回调函数拥有额外的状态值,以便在它的内部使用到。
内联回调函数
当你编写使用回调函数的代码的时候,担心很多小函数的扩张可能会弄乱程序控制流。你希望找到某个方法来让代码看上去更像是一个普通的执行序列。
通过使用生成器和协程可以使得回调函数内联在某个函数中。
为了演示说明,假设你有如下所示的一个执行某种计算任务然后调用一个回调函数的函数
接下来让我们看一下下面的代码,它包含了一个 Async 类和一个 inlined_async装饰器:
这两个代码片段允许你使用 yield 语句内联回调步骤。比如:
如果你调用 test() ,你会得到类似如下的输出:
你会发现,除了那个特别的装饰器和 yield 语句外,其他地方并没有出现任何的回调函数 (其实是在后台定义的)。
本小节会实实在在的测试你关于回调函数、生成器和控制流的知识。 首先,在需要使用到回调的代码中,关键点在于当前计算工作会挂起并在将来的某个时候重启 (比如异步执行)。当计算重启时,回调函数被调用来继续处理结果。apply_async() 函数演示了执行回调的实际逻辑,尽管实际情况中它可能会更加复杂(包括线程、进程、事件处理器等等)。 计算的暂停与重启思路跟生成器函数的执行模型不谋而合。具体来讲,yield 操作会使一个生成器函数产生一个值并暂停。接下来调用生成器的 __next__() 或 send()方法又会让它从暂停处继续执行。 根据这个思路,这一小节的核心就在 inline_async() 装饰器函数中了。关键点就是,装饰器会逐步遍历生成器函数的所有 yield 语句,每一次一个。为了这样做,刚开始的时候创建了一个 result 队列并向里面放入一个 None 值。然后开始一个循环操作,从队列中取出结果值并发送给生成器,它会持续到下一个 yield 语句,在这里一个 Async 的实例被接受到。然后循环开始检查函数和参数,并开始进行异步计算apply_async() 。然而,这个计算有个最诡异部分是它并没有使用一个普通的回调函数,而是用队列的 put() 方法来回调。 这时候,是时候详细解释下到底发生了什么了。主循环立即返回顶部并在队列上执行 get() 操作。如果数据存在,它一定是 put() 回调存放的结果。如果没有数据,那么先暂停操作并等待结果的到来。这个具体怎样实现是由 apply_async() 函数来决定的。如果你不相信会有这么神奇的事情,你可以使用 multiprocessing 库来试一下,在单独的进程中执行异步计算操作,如下所示:
实际上你会发现这个真的就是这样的,但是要解释清楚具体的控制流得需要点时间了。 将复杂的控制流隐藏到生成器函数背后的例子在标准库和第三方包中都能看到。比如,在 contextlib 中的 @contextmanager 装饰器使用了一个令人费解的技巧,通过一个 yield 语句将进入和离开上下文管理器粘合在一起。另外非常流行的 Twisted 包中也包含了非常类似的内联回调。
访问闭包中定义的变量
类与对象
元编程
pycharm基础设置
如果已经有setting.zip可以直接导入即可
./res/5. python基础知识/settings.zip
pycharm激活
秘钥: lookdiv.com
git配置
配置git路径
Setting->Version Control->git
Path to Git executable: S:\Git\cmd\git.exe
python模板设置
打开Setting->Editor->File and Code Templates->Files->Python Script
配置如下信息(修改作者名,其他无需修改):
快捷键设置
Reformat Code
Ctrl+Alt+F
格式化代码
Close
Ctrl+R
关闭当前py文件窗口
Split Vertically
Ctrl+Shift+向右箭头
垂直切分窗口
Split Horizontally
Ctrl+Shift+向左箭头
水平切分窗口
Git Pull
Ctrl+Shift+L
git pull
Git commit File
Ctrl+K
git commit
Git Commit and push
Ctrl+Shift+K
git push
Change font size
ctrl+N->Actions->Change font size with Ctrl+Mouse Wheel
Show in Explorer
Crtl+Shift+S
项目依赖
导出依赖
安装pipreqs
导出依赖, 强制覆盖原先的依赖
安装依赖
安装依赖库
离线安装
单个下载
批量下载
批量安装已经导出的包
其中 --no-index 代表忽视pip 忽视默认的依赖包索引
--find-links= 代表从你指定的目录寻下找离线包
Nginx
什么是Nginx?
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。2011年6月1日,nginx 1.0.4发布。
其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。在全球活跃的网站中有12.18%的使用比率,大约为2220万个网站。
Nginx 是一个安装非常的简单、配置文件非常简洁(还能够支持perl语法)、Bug非常少的服务。Nginx 启动特别容易,并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够不间断服务的情况下进行软件版本的升级。
Nginx代码完全用C语言从头写成。官方数据测试表明能够支持高达 50,000 个并发连接数的响应。
Nginx作用
Http代理
Http代理,反向代理:作为web服务器最常用的功能之一,尤其是反向代理。
正向代理
 反向代理
反向代理

负载均衡
Nginx提供的负载均衡策略有2种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash。扩展策略,就天马行空,只有你想不到的没有他做不到的。
轮询
加权轮询

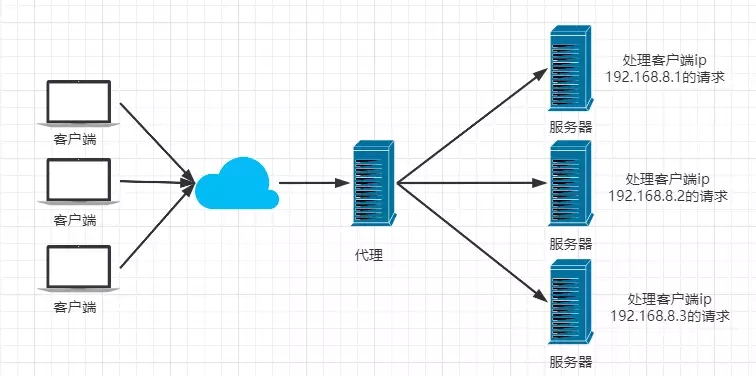
iphash
对客户端请求的ip进行hash操作,然后根据hash结果将同一个客户端ip的请求分发给同一台服务器进行处理,可以解决session不共享的问题。
fair
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
url_hash
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
动静分离
动静分离,在我们的软件开发中,有些请求是需要后台处理的,有些请求是不需要经过后台处理的(如:css、html、jpg、js等等文件),这些不需要经过后台处理的文件称为静态文件。让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作。提高资源响应的速度。

基本使用
配置监听
nginx的配置文件是conf目录下的nginx.conf,默认配置的nginx监听的端口为80,如果80端口被占用可以修改为未被占用的端口即可。
 当我们修改了nginx的配置文件nginx.conf 时,不需要关闭nginx后重新启动nginx,只需要执行命令
当我们修改了nginx的配置文件nginx.conf 时,不需要关闭nginx后重新启动nginx,只需要执行命令 nginx -s reload 即可让改动生效
关闭nginx
如果使用cmd命令窗口启动nginx, 关闭cmd窗口是不能结束nginx进程的,可使用两种方法关闭nginx
(1)输入nginx命令 nginx -s stop(快速停止nginx) 或 nginx -s quit(完整有序的停止nginx)
(2)使用taskkill taskkill /f /t /im nginx.exe
Nginx常用命令
指令
防火墙
演示
最后更新于