

python多进程
python多进程
基本概念
Python中的多进程是通过
multiprocessing包来实现的,和多线程的threading.Thread差不多,它可以利用multiprocessing.Process对象来创建一个进程对象这个进程对象的方法和线程对象的方法差不多也有start(),run(),join()等方法,其中有一个方法不同Thread线程对象中的守护线程方法是setDeamon,而Process进程对象的守护进程是通过设置daemon属性来完成的
与多线程的共享式内存不同,由于各个进程都是相互独立的,因此进程间通信再多进程中扮演这非常重要的角色,Python中我们可以使用multiprocessing模块中的pipe、queue、Array、Value等等工具来实现进程间通讯和数据共享,但是在编写起来仍然具有很大的不灵活性
任务类型
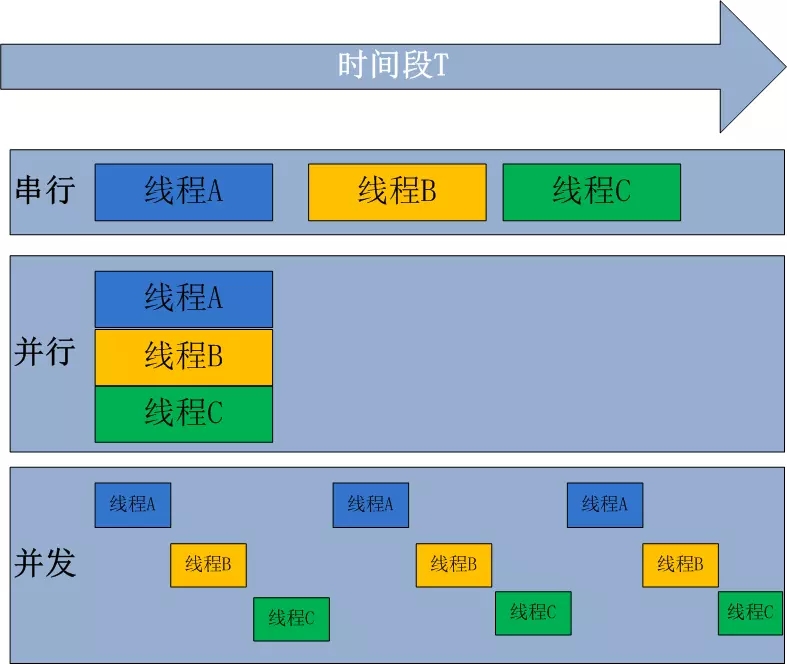
同步与异步
同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息 那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去
异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态 当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率
IO密集和计算密集
对于IO密集型任务: python的多线程能够节省时间
对于计算(CPU)密集型任务: Python的多线程并没有用处,建议使用多进程
其他组合搭配
python使用多核,即开多个进程
方法一: 协程+多进程,使用方法简单,效率还可以,一般使用该方法
协程yield是你自己写的,是自己定义什么时候切换进程
方法二:IO多路复用,使用复杂,但效率很高,不常用
多进程相关模块
python多线程低效原因
GIL的全称是 Global Interpreter Lock(全局解释器锁),来源是 Python 设计之初的考虑,为了数据安全所做的决定
某个线程想要执行,必须先拿到 GIL,我们可以把 GIL 看作是“通行证”,并且在一个 Python 进程中,GIL 只有一个
拿不到通行证的线程,就不允许进入 CPU 执行
目前 Python 的解释器有多种,例如:
CPython:CPython 是用C语言实现的 Python 解释器,作为官方实现,它是最广泛使用的 Python 解释器
PyPy:PyPy 是用RPython实现的解释器。RPython 是 Python 的子集, 具有静态类型。这个解释器的特点是即时编译,支持多重后端(C, CLI, JVM)。PyPy 旨在提高性能,同时保持最大兼容性(参考 CPython 的实现)
Jython:Jython 是一个将 Python 代码编译成 Java 字节码的实现,运行在JVM(Java Virtual Machine)上。另外,它可以像是用 Python 模块一样,导入 并使用任何Java类
IronPython:IronPython 是一个针对 .NET 框架的 Python 实现。它 可以用 Python 和 .NET framewor k的库,也能将 Python 代码暴露给 .NET 框架中的其他语言
GIL 只在 CPython 中才有,而在 PyPy 和 Jython 中是没有 GIL 的
注意: 每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源
这就导致打印线程执行时长,会发现耗时更长的原因
并且由于 GIL 锁存在,Python 里一个进程永远只能同时执行一个线程(拿到 GIL 的线程才能执行),这就是为什么在多核CPU上,Python 的多线程效率并不高的根本原因
多进程实现方式
Process
普通Process
上面的代码开启了5个子进程去执行函数,我们可以观察结果,是同时打印的,这里实现了真正的并行操作,就是多个CPU同时执行任务。
我们知道进程是python中最小的资源分配单元,也就是进程中间的数据,内存是不共享的,每启动一个进程,都要独立分配资源和拷贝访问的数据,所以进程的启动和销毁的代价是比较大了,所以在实际中使用多进程,要根据服务器的配置来设定。
继承Process
通过类继承的方法来实现的,python多进程的第二种实现方式也是一样的,效果和第一种方式一样
Process类的其他方法
进程池
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了
其他进程池
多进程通信
进程是系统独立调度核分配系统资源(CPU、内存)的基本单位,进程之间是相互独立的,每启动一个新的进程相当于把数据进行了一次克隆,子进程里的数据修改无法影响到主进程中的数据,不同子进程之间的数据也不能共享,这是多进程在使用中与多线程最明显的区别
但是难道Python多进程中间难道就是孤立的吗?
当然不是,python也提供了多种方法实现了多进程中间的通信和数据共享(可以修改一份数据)
进程队列Queue
上面的代码结果可以看到我们主进程中可以通过Queue获取子进程中put的数据,实现进程间的通信
JoinableQueue队列
JoinableQueue([maxsize]):这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理
通知进程是使用共享的信号和条件变量来实现的
参数介绍:
maxsize: 是队列中允许最大项数,省略则无大小限制
方法介绍:
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理 如果调用此方法的次数大于从队列中删除项目的数量将引发ValueError异常
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理 阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
示例代码
结果输出
管道Pipe
Pipe的本质是进程之间的用管道数据传递,而不是数据共享,这和socket有点像
pipe()返回两个连接对象分别表示管道的两端,每端都有send()和recv()函数
如果两个进程试图在同一时间的同一端进行读取和写入那么,这可能会损坏管道中的数据
管道是数据不安全的,多个进程同时收发数据可道引起数据异常,这时候就应该配合锁使用
上面可以看到主进程和子进程可以相互发送消息
Managers
Queue和Pipe只是实现了数据交互,并没实现数据共享,即一个进程去更改另一个进程的数据,那么就要用到Managers
可以看到主进程定义了一个字典和一个列表,在子进程中,可以添加和修改字典的内容 在列表中插入新的数据,实现进程间的数据共享,即可以共同修改同一份数据
注意事项
无法调用多层生成器(待验证)
几个问题:
以上代码 若有多个生产者 就会各自拥有自己的数据生成器,导致数据重复
有些定义的方法 好像会使程序卡住
最后更新于